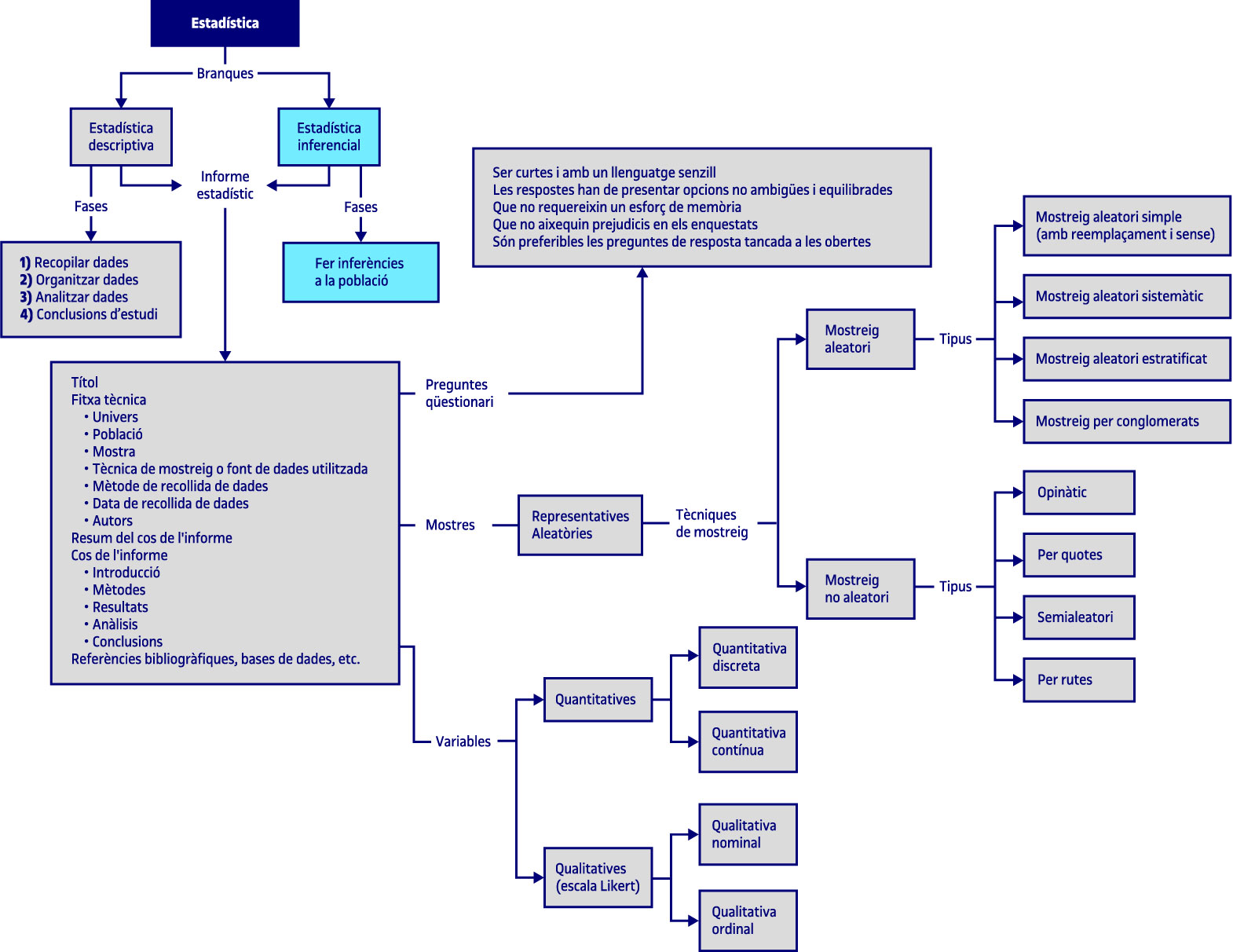
8.3. Técnicas de muestreo
8.3.7. Muestreos no aleatorios
En este tipo de muestreo se tiene en cuenta el criterio del investigador. Esto quiere decir que la representatividad no está garantizada. Como indica Vinuesa (Ibid., pág. 189), con este tipo de muestreo los componentes del universo no tienen las mismas posibilidades de formar parte del estudio. El error puede ser mayor con este tipo de muestreos.
Tipo de muestreos no aleatorios:
Opinático
Preguntas al que te apetezca y que pase por allí.
Muestreo por cuotas
Cuando la estratificación no es posible o resulta muy cara, y también en casos en los que no se dispone de una lista de la población a investigar, se puede recurrir al llamado muestreo por cuotas. Es uno de los más utilizados gracias a su facilidad y rapidez. En la primera fase es un muestreo opinático y se fijan límites para diversificar la muestra.
Sin embargo, como se ha señalado, la fiabilidad presenta problemas, como, por ejemplo, que se acuda a personas cercanas para aplicar las técnicas de recolección de información y esto imponga un sesgo en la investigación.
Muestreo semialeatorio
Es mezcla de uno aleatorio y de uno no aleatorio.
Muestreo por rutas
Casi es aleatorio, consiste en que el que pregunta tiene como un plano con unas leyes de movimiento dentro del plano.
Este tipo de muestreos los vamos a rechazar, porque para que una muestra se considere válida y por tanto el estudio estadístico en torno a ella, debe cumplir las siguientes condiciones:
- Ser representativa
Esta condición está asociada al tamaño de la muestra. Es evidente que cuanto más grande sea el tamaño de la muestra, más se aproximará al tamaño de la población y por tanto, más representativa será. Pero en la mayoría de los estudios, no es óptimo estudiar toda la población, ni tamaños de muestra muy grandes, por eso se recurren a las técnicas de muestreo.
- Ser aleatoria
Es decir, cualquier elemento de la población puede ser elegido para formar parte de la muestra porque todos tienen la misma probabilidad en cuanto a elección, no hay unos elementos más probables que otros. En caso contrario, corremos el riesgo de elegir elementos para la muestra que cumple una determinada condición, con lo que estaríamos falseando los resultados estadísticos y el estudio sería declarado no válido. En el caso de que la muestra no sea aleatoria, se dice que se han cometido errores de sesgo.
Resumiendo, a modo de esquema: